【Dify】イテレーションノードとCSV一括処理の正しい使い分け方
 blog
blog
Difyでワークフローを構築していると、「同じ処理を複数のデータに対して繰り返したい」という場面に必ず遭遇します。この時、候補に挙がるのが「イテレーション(繰り返し)ノード」と「CSV一括処理(バッチ実行)」です。
どちらも「繰り返す」という目的は同じですが、仕組みや適したユースケースは全く異なります。
この記事では、Difyを使った業務自動化やAIアプリ開発において、この2つをどう使い分けるべきか、具体的な実例を交えて解説します。
結論:ループを回す「範囲」と「データ形式」が違う
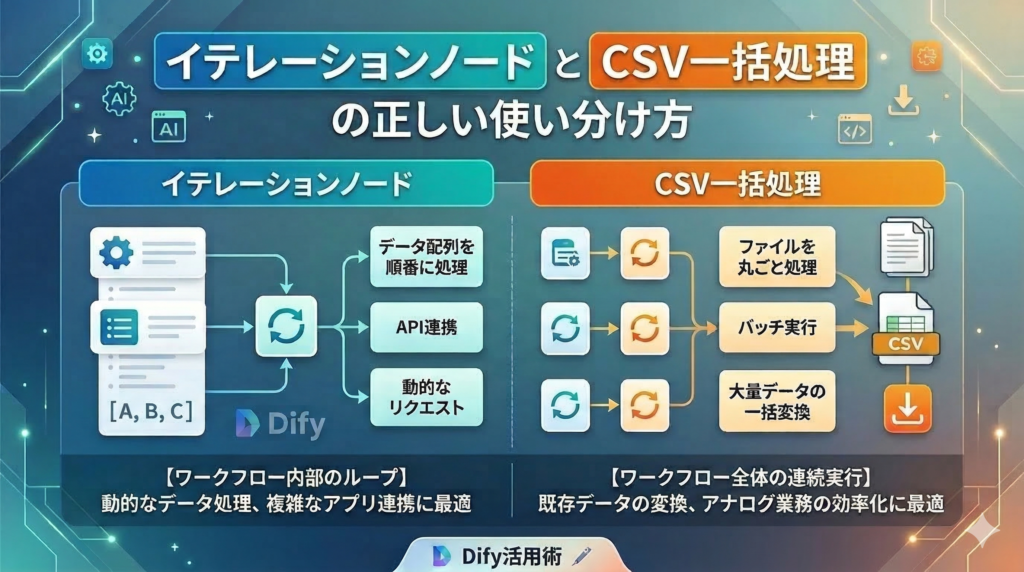
最大の違いは、ループ処理が行われる**「スコープ(範囲)」と、扱う「データの入出力形式」**です。
- イテレーションノード: ワークフローの「内部」で特定のステップだけを繰り返す。入力・出力は「配列(Array)」。
- CSV一括処理: ワークフロー「全体」を外側から複数回実行する。入力・出力は「CSVファイル」。
それぞれの特徴を詳しく見ていきましょう。
イテレーションノードとは?(ワークフロー内部のループ)
イテレーションノードは、ワークフローの途中の一部として機能します。プログラミングにおける for ループや map 関数と同じような役割を持ちます。
配列(Array)データを入力として受け取り、その要素一つひとつに対してLLMなどの処理を実行し、最終的にまた配列として結果を出力します。
CSV一括処理とは?(ワークフロー全体のループ)
完成したワークフロー(またはチャットフロー)を、アップロードしたCSVの行数分だけ独立して連続実行する機能です。
1行目の処理と2行目の処理は完全に切り離されており、手作業で1回ずつ入力して実行する手間を省くための機能と言えます。
実践!ユースケース別の最適な選び方
では、実際の業務や開発において、どちらを選ぶべきでしょうか。具体的なパターンで解説します。
パターン1:手元のアナログデータを一気に変換したい → 【CSV一括処理】
すでに手元にある大量のデータを一括で処理したい場合は、CSV一括処理が圧倒的に手軽です。
具体例:
- 過去1年分の「市民からの要望(数千件)」が入力されたExcel/CSVを、AIで一気に「カテゴリ分類」や「要約」する。
- 商品リストのCSVを読み込ませ、全件分のキャッチコピーを自動生成してCSVでダウンロードする。
複雑なワークフローを組む必要はなく、シンプルなプロンプトを用意するだけで、すぐに業務効率化が実現できます。
パターン2:Webアプリのバックエンドや動的処理 → 【イテレーションノード】
複雑なシステムへの組み込みや、ユーザーのアクションをトリガーにして動的にデータを処理する場合は、イテレーションノードが必須になります。フロントエンドエンジニアの視点から言うと、API経由で結果を受け取って画面に描画するならこちら一択です。
具体例①:シフト作成アプリの裏側
シフト作成のような複雑な条件が絡むタスクでは、全職員のデータを一度にLLMに渡すと混乱(ハルシネーション)を起こします。
そこで、職員ごと、あるいは日付ごとにデータを配列化し、イテレーションを使って少しずつLLMに処理(または個別メッセージの生成など)をさせることで、精度を劇的に向上させることができます。
具体例②:庁内アンケートなど、Excelシートごとの自動解析
「1つのExcelファイルの中に、部ごとにシートが分かれている」というケースはよくあります。
ユーザーがファイルを1回アップロードするだけで、裏側のPythonコードがシートごとにデータを分割・配列化し、イテレーションノードで「部ごとの課題抽出」を反復実行する。
最終的に配列(JSON形式)でフロントエンドに返し、画面上に綺麗に表示させるといった高度なUXを実現できます。
イテレーションノードを使いこなす実装のコツ
イテレーションノードを実務で使う上で、最も重要なポイントがあります。それは「Python(コード実行)ノードとの組み合わせ」です。
イテレーションノードは必ず「Array(配列)」を入力として受け取る必要があります。しかし、ユーザーの入力テキストやファイルの生データはそのままでは配列になっていません。
そのため、イテレーションの直前に「コード実行ノード」を配置し、Pythonでデータを扱いやすい配列形式( ["A", "B", "C"] やJSONの配列 )に変換・前処理してあげるのがベストプラクティスです。
複雑な計算やデータ整形はPythonに任せ、自然言語の解釈や生成だけをイテレーション内のLLMに任せることで、安定した強力なワークフローが完成します。
まとめ
- CSV一括処理: 既存データの一括変換、アナログなデータ入力作業の代替に最適。出力はファイル。
- イテレーションノード: Webアプリの内部ロジック、動的なデータの処理、複数結果の統合に最適。出力は配列(JSON等)。
用途に合わせて適切な繰り返し処理を選択し、Difyによる業務自動化をさらに加速させましょう!