Difyローカル版でOllamaを使い、独自開発したモデルを動かす方法
 blog
blog
Difyをローカルに構築できるようになると、次に試したくなるのが、自分の端末で動かしているローカルモデルとの連携です。
Difyはワークスペース単位でモデルプロバイダーを設定でき、Ollama経由のローカルモデルも利用できます。そのため、DifyをAIアプリの開発画面として使いながら、推論は自分のPC上のモデルに任せる構成を作ることができます。
今回は、Dockerでローカル構築したDifyと、Mac上で動かしているOllamaを接続し、さらに独自に作成したOllamaモデルをDifyから使うまでの流れをまとめます。なお、OllamaではModelfileを使ってカスタムモデルを作成でき、ollama create コマンドで独自モデルとして登録できます。
ローカルモデルの開発については、下記の記事で紹介をしています

まずは前提を整理
今回の構成では、DifyはDocker Composeで起動したコンテナ内のアプリとして動いています。一方でOllamaは、Mac本体側で動いています。Docker Desktopでは、コンテナからホスト上のサービスへ接続する際に host.docker.internal という特別な名前を使うことができます。
このため、DifyからOllamaにつなぐときは、単純に localhost を指定するのではなく、Dockerコンテナから見たホスト側アドレスを使う必要があります。ローカル連携で最初につまずきやすいのは、この接続先の違いです。
Ollama側の基本仕様
OllamaのAPIは通常 http://localhost:11434 で利用でき、モデル一覧は /api/tags で取得できます。また、Ollamaはデフォルトで 127.0.0.1:11434 にバインドされるため、そのままではDockerコンテナ側からアクセスできない場合があります。
そのため、Difyから接続したい場合は、OllamaがMac本体のローカルだけで閉じないように設定しておく必要があります。macOSでは、launchctl setenv を使って環境変数を設定する方法が公式に案内されています。
(参考:Ollama公式ドキュメント「FAQ」) (Ollama Documentation)
手順1:OllamaをDocker側から見えるようにする
まず、ターミナルで次のコマンドを実行します。
launchctl setenv OLLAMA_HOST "0.0.0.0:11434"
この設定により、Ollamaの待ち受け先を 127.0.0.1 ではなく 0.0.0.0:11434 に変更できます。その後、Ollamaアプリをいったん終了し、再起動します。
(参考:Ollama公式ドキュメント「FAQ」) (Ollama Documentation)
手順2:独自モデルがOllamaに登録されているか確認する
次に、使いたい独自モデルがOllama側に登録されているかを確認します。モデル一覧はCLIの ollama ls でも確認できますが、APIでは curl http://localhost:11434/api/tags で取得できます。
(参考:Ollama公式ドキュメント「List models」)
curl http://localhost:11434/api/tags
ここで、たとえば sarashina-koki:latest のような独自モデル名が見えていれば準備OKです。カスタムモデルをまだ作っていない場合は、Modelfileを作成し、ollama create でモデルを生成します。
手順3:DifyでOllamaをモデルプロバイダーとして設定する
Difyでは、アプリごとに直接モデルを入れるのではなく、まずワークスペースのモデルプロバイダーとして接続先を設定します。Difyのモデルプロバイダーは、ワークスペース内のすべてのアプリから利用される共通基盤です。
Difyの画面では、次の順で設定します。
- 設定
- モデルプロバイダー
- Ollama
- 認証情報を追加
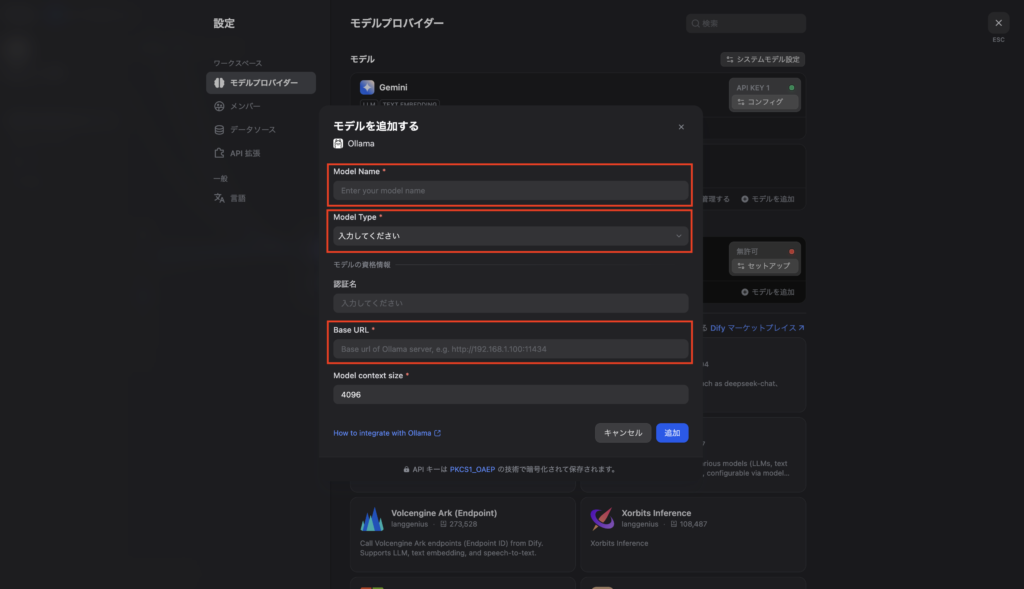
このとき、Base URL には次を入力します。
http://host.docker.internal:11434DifyのOllama設定では、通常のサーバーURLとして http://localhost:11434 が案内されていますが、今回はDifyがDockerコンテナ内で動いているため、ホスト側のOllamaへ接続するために host.docker.internal を使います。
下記の赤枠内に情報を入力します。
手順4:モデル名は「Ollama」ではなく実際のモデル名を入れる
ここで注意したいのが、モデル名の入力内容です。Ollama はあくまでプロバイダー名であり、モデル名ではありません。入力するのは、/api/tags などで確認できる実際のモデル名です。
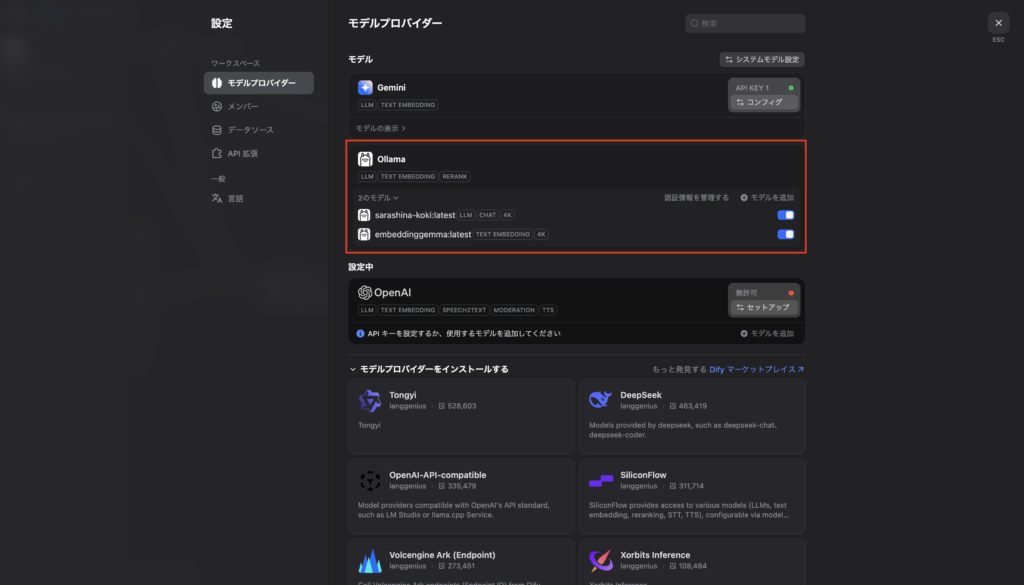
たとえば、私の場合だったら会話用の独自モデルなら sarashina-koki:latest、埋め込み用モデルなら embeddinggemma:latest のように指定します。DifyではOllama経由のローカルモデルとローカル埋め込みモデルの両方を扱うことができます。
設定ができるとOllamaに登録したモデルが表示されます
手順5:接続確認をする
設定後は、本当にDifyコンテナからOllamaへ届くかを確認しておくと安心です。今回のようなDocker Compose構成なら、APIコンテナからOllamaのモデル一覧を叩いて確認できます。
docker exec -it docker-api-1 curl http://host.docker.internal:11434/api/tags
ここでJSONが返ってくれば、ネットワーク的にはDifyからOllamaへ到達できています。もし返らない場合は、Ollama側が 0.0.0.0:11434 で待ち受けていない、あるいは再起動がまだ反映されていない可能性があります。
手順6:Difyのアプリで独自モデルを選ぶ
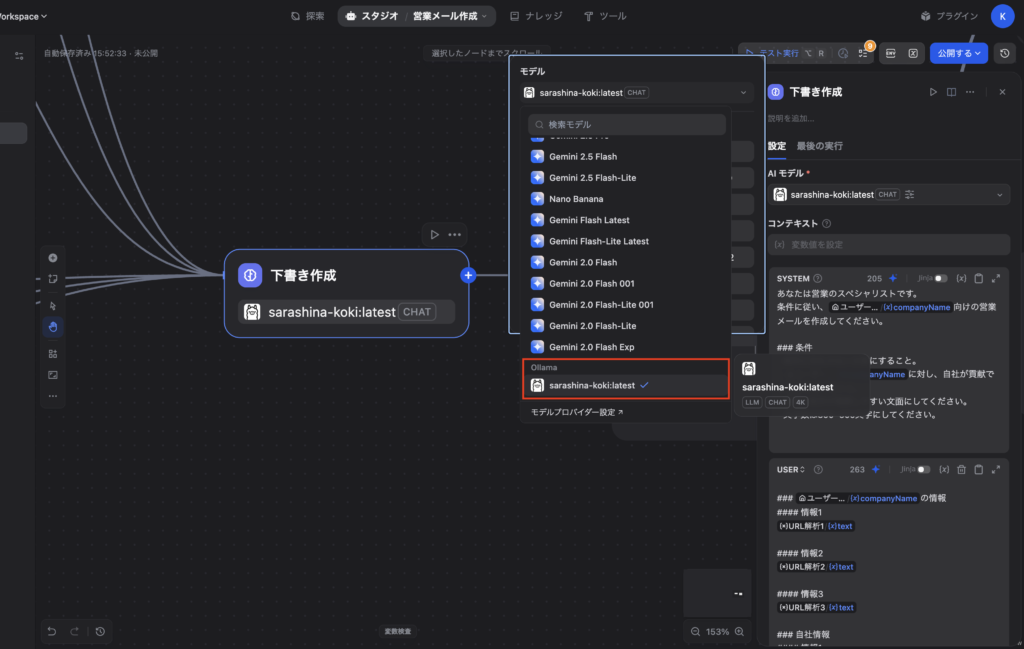
接続が完了したら、Difyでチャットアプリやワークフローアプリを作成し、モデル選択画面で先ほど設定したOllamaモデルを選びます。Difyはワークスペースレベルで設定したモデルプロバイダーを、複数のアプリから共通利用できる設計です。
うまく追加ができていれば、下のような感じで「モデル」に自分が追加したモデルが表示されて選べるようになります。
ここまでできれば、DifyのUIでアプリを組み立てつつ、裏側の推論は自分で育てたOllamaモデルに任せるという流れが実現できます。ローカルで完結する環境を整えたい場合にも、相性のよい構成です。
まとめ
Difyローカル版で独自モデルを使うときの流れは、意外とシンプルです。大きく見ると、やることは次の3つです。
- Ollamaで独自モデルを作成し、一覧に表示される状態にする
- Ollamaを
0.0.0.0:11434で待ち受けるようにする - DifyのOllama設定で
http://host.docker.internal:11434を指定し、実際のモデル名を使う
この構成を作っておくと、Difyのアプリ開発のしやすさと、Ollamaのローカル実行・独自モデル運用の自由度を両立しやすくなります。
(参考:Dify公式ドキュメント「モデルプロバイダー」「Deploy Dify with Docker Compose」、Ollama公式ドキュメント「Modelfile Reference」「FAQ」)